I spent some time last night learning about and implementing split DNS on SRXes via
Junos’ proxy-dns feature, and ran into some interesting complications.
Here’s a diagram of the environment I was working on:
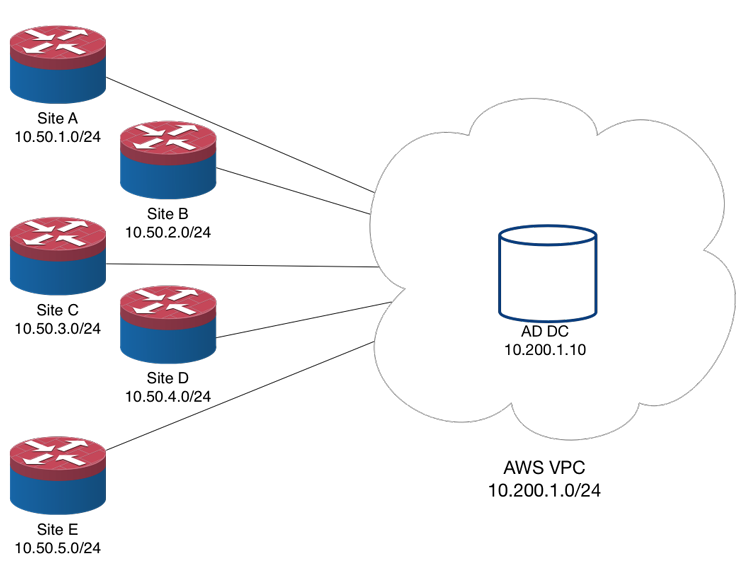
This environment consists of five branches, each with an SRX210. There’s a full mesh of IPsec VPN tunnels between them (10 links total, not pictured). Last night’s task was building VPN tunnels from each site to an AWS VPC so that the MS guys on my team could build an AD domain in AWS. Amazon makes this extremely easy, even providing example Junos configs, but even better you can download automatically generated Junos configs with your tunnel’s info prepopulated. The entire process took about 30 minutes for all five sites.
It got interesting when setting up split DNS. The goal here is to have the corporate networks at all five locations able to work with a domain controller in AWS, but without hairpinning all DHCP and DNS traffic through the VPN tunnels to AWS. We can leave DHCP on the SRXes, but AD requires DNS to function, so we need it to at least resolve requests for the AD domain. The natural solution is split DNS: requests for any names in company.com. are forwarded to the domain controller(s), and all other requests are handled by public DNS. Users on the internal network should be using the local firewall as their resolving nameserver (passed via DHCP), and company.com should resolve to its AWS internal IP address of 10.200.1.10 rather than the public A record of 74.122.237.76, company.com’s webserver.
Juniper has some docs here and here, and there are a couple quick articles I also took a look at.
Here’s the config:
tylerkerr@site-a-srx210> show configuration system services dns dns-proxy
interface {
vlan.10;
}
default-domain * {
forwarders {
8.8.8.8;
8.8.4.4;
}
}
default-domain company.com {
forwarders {
10.200.1.10;
}
}
I threw the config in, committed, and tested. dig company.com @10.50.1.1 returned 74.122.237.76, the external address – not working. On first attempt there was a delay of about three seconds – this ended up being very important, although I didn’t realize it until later. I cleared the dns-proxy cache (clear system services dns-proxy cache), which didn’t resolve the issue but did reintroduce the three-second delay on first resolution.
At this point I reread the config as well as the blog posts and KB articles to make sure I wasn’t missing something. A guess was that the order of default-domain statements mattered, a la ACLs, but everything I saw indicated otherwise, that this is more of a longest-prefix style ruleset. I tried breaking the config up into a ‘view’ statement, matching clients only in specific CIDR ranges, but the results were identical.
I set up a trace for destination-prefix 10.200.1.10/32 and reproduced the issue. I immediately saw that the source IP for the DNS queries was the IP address for st0.8, the address that AWS’ automatically generated VPN config files gave me: 169.254.45.122, a link-local address. Since I have a static route for the VPC, the SRX was correctly sourcing the queries from this link-local address, but there was no way for the responses to come back in for a number of reasons. This meant that the SRX tried three queries to 10.200.1.10, each timing out after one second, before falling back to Google DNS. This explains the initial symptoms above – a three-second delay followed by a response with the public IP address.
My next plan was to attempt to change the source IP for outbound dns-proxy queries. Some reading pointed me towards the default-address-selection selection, which evidently tells system services to use the firewall’s loopback address rather than sourcing based on outbound interface. I set the loopback address to an unused IP in the corporate subnet, which immediately let DNS flow between the corporate network and AWS, but broke other system services (like all other DNS to Google) since they were now being sourced from an RFC1918 address.
Some more googling found me this j-nsp thread, which was extremely helpful. The key suggestion further down was to “number the st0 interface with a /32 from the corporate range and source my queries from there.” I wasn’t actually sure that this would work – did Amazon give me specific link-local addresses for a reason? would changing these break the tunnels? – but I gave it a try. After a brief dropout while the IPsec tunnel re-established itself, communication to AWS came right back up, meaning that AWS doesn’t care how my side of the tunnel is addressed.
However, after committing this change, I was no longer able to query the SRX for ANY DNS records, getting this from dig:
;; WARNING: recursion requested but not available
I was completely at a loss for this, checking the differences between all of my commits trying to find when DNS stopped working and what could have broken it. I fixed it by committing a “deactivate system services dns dns-proxy” then a reactivation – just a bug.
After this, everything was working properly – company.com resolved to its internal address from the corporate network, other DNS traffic was properly forwarded to Google DNS, and no huge workarounds were necessary.
PelliX
2019-08-01 — 13:39
Came to the same conclusion and ‘solution’ here. You can however `restart named-service` instead of committing a configuration with the dns-proxy disabled and then rolling back again. Just saying.