One of my clients’ networks is made up of a number of small offices, all of which have VPN tunnels from their SRX210s to AWS, where their AD/file/application servers live. After the cloud migration, I was getting complaints from users of intermittent dropouts of AWS connectivity. They were experiencing this primarily as RDP sessions dropping, which could have many different causes, but I looked into it a bit. I was able to observe a couple dropouts of a few seconds each, but couldn’t find any causes or correlations at a glance.
Amazon has a great writeup on the requirements and procedures for a site-to-site VPN between your equipment and a VPC, but to sum it up, you can essentially provide Amazon with a few pieces of info (public IP address, prefixes to route, firewall vendor/version) and Amazon will provide a list of set commands that only require minor edits. This is how I built these tunnels, and after changing interface names and IP addresses everything was up and running except for proxy-dns. I wrote about troubleshooting and resolving that here, but essentially (and important to the above issue) I had to give the interfaces on my side of the tunnel addresses in my corporate network rather than the link-local addresses that the autogenerated Amazon configs provided.
Back to the issue at hand – after observing intermittent dropouts and not finding immediately apparent issues, I took a look at our network monitoring setup (LogicMonitor), which is essentially just consuming SNMP from a number of our firewalls/routers/switches. The SRXes were showing interface flaps on the st0 interfaces that correspond to the AWS tunnels, although these were very frequent, much more frequent than any observed or reported issues. LogicMonitor is (without tuning) noisier than it needs to be, at least on Juniper gear, so I didn’t make too much of this, although inspecting the tunnels in the AWS console showed very recent (minutes) “status last changed” times. Some more cursory investigation on the firewalls found nothing, so I decided to focus on the VPN tunnel config. After a significant amount of troubleshooting by disabling one of the two links and monitoring one link at a time.
This showed me the actual issue, which is fascinating – the link was going down for exactly ten seconds, once every two minutes:
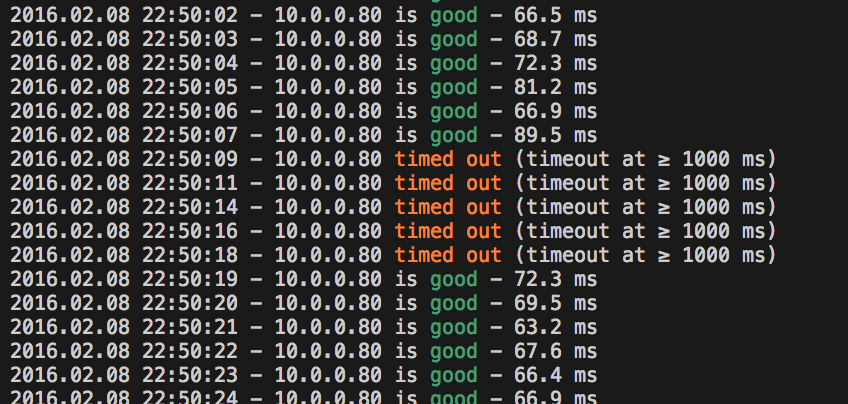
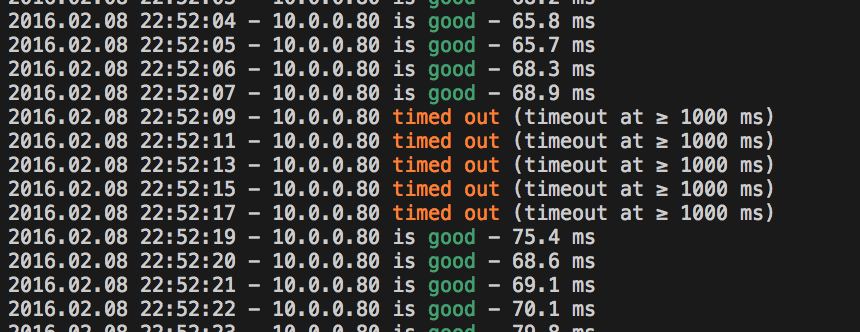
By watching the tunnel’s security-association on the firewall, I could see the cause of the link loss: AWS’ default config for a Junos device includes enabling vpn-monitor on the IPsec tunnel. Because of the tunnel address config mentioned above, vpn-monitor won’t work in this setup – the probes will not be returned, and the tunnel will be taken down and rebuilt as it appears to have failed. This is the cause of the perfectly regular dropouts on each tunnel.
So why was this causing intermittent and hard-to-identify outages? Beat frequency. Each link was experiencing (roughly) 10 seconds of downtime (roughly) every two minutes. Most of the time, these outages didn’t line up, and traffic continued to flow over the remaining link. However, because internet traffic is nondeterministic, the difference in tunnel rebuild times would cause each link’s outage time to shift slightly each cycle. Eventually, like turn signals or windshield wipers, these similar-but-not-exactly-identical periods would line up for a few seconds causing a complete outage.
Disabling vpn-monitoring for these tunnels resolved the issue completely. A very satisfying issue to troubleshoot.