I found myself with some spare time last week, and decided to entertain myself by implementing AES in Go from scratch. I’ve played with Go a little before, specifically because I wanted a way to programmatically output the n th prime number (where nthprime(1) returns 2, nthprime(2) returns 3, etc)) and Python’s way too slow for crunching of that magnitude. It works well, though it’s fairly apparent that it’s the first thing I wrote in Go and there’s some serious StackExchange copy/pasting going on.
A brief interlude on Go vs. Python performance – while building nthprime.go (above), I ported the core operation (a Sieve of Eratosthenes) basically line-for-line to Python so that I could compare performance between the two languages. Here’s the sieve in Go, and here it is in Python. This was purely out of curiosity – you can easily look up benchmarks comparing any two programming languages, but it’s way more interesting to do it with your own code on your own machine.
For my code, Go is about 40x faster than Python:
Getting back to the subject, cryptography is a favorite subject of mine, and while I feel pretty comfortable with classic public-key crypto and the high- and medium-level concepts of symmetric ciphers, I figured I could stand to learn about the low-level guts of the world’s most popular block cipher. I chose to implement in Go for two reasons: 1) more practice with Go, and 2) while I love Python, it’d feel a bit wrong to implement something so performance-sensitive in a (relatively) slow language.
I got what I wanted – I learned a ton about AES and the underlying math, and I feel much more comfortable with Go than I did a week ago.
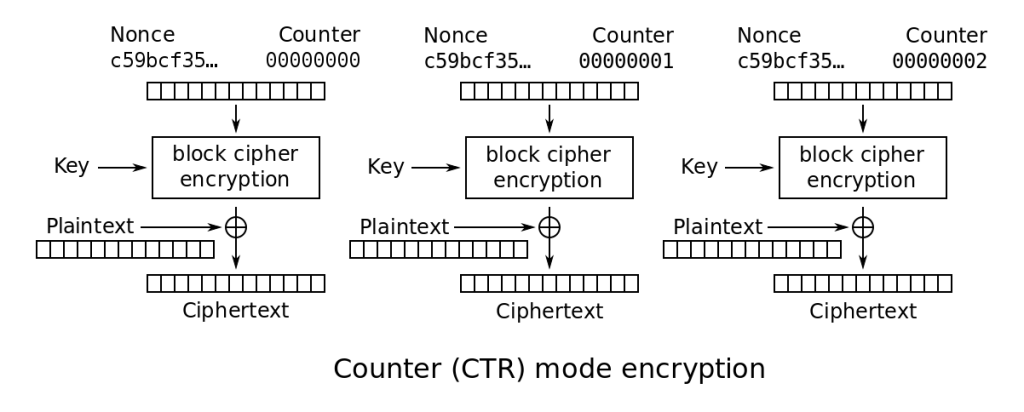
It’s purely a toy implementation with hardcoded test cases – it would take slightly more work to have it operate on arbitrary data (files/args/stdin), but real-world utility was not the point of this exercise. I’m already quite comfortable with block cipher modes of operation; my primary cryptographic interest was looking inside the black box of “perform block encryption” in every mode of operation diagram. Additionally, while I have verified that the encrypt/decrypt results of my code match standard implementations of AES, for obvious reasons it’s not a great idea to slot homebrew implementations of crypto primitives into anything that matters. I do plan on eventually using my implementation instead of Cryptography.io in my Python solutions to the Matasano crypto challenges, though I’ll have to figure out the best way to call binaries from Python without too much of a performance hit. That’ll just be for fun, though.
Here are some of the most interesting things that I learned in the process:
Galois fields are really hard to grasp intuitively. I ended up using lookup tables rather than implementing Galois multiplication/exponentiation/inversion, which I initially felt bad about (I wanted to implement purely from the Wikipedia description, no pseudocode or ports for reference).
It turns out that pretty much every production implementation of AES uses lookup tables and doesn’t do the Galois field operations ‘live’. As I learned from this great blog post, there are multiple degrees to which lookup tables can be substituted for live finite field math: none (Galois field operations applied at nearly every stage), S-boxes only (two 256-byte tables), S-boxes and MixColumns (S-boxes plus six more 256-byte tables, two for forward and four for inverse Galois multiplication), and full lookup tables (S-boxes, plus large lookup tables for the entire round operations of SubBytes, MixColumns, and ShiftRows).
I spent some time trying to understand computation in Galois fields, but was eventually faced with three choices:
1) spend a significant amount of time learning and getting comfortable with the underlying math so I could implement from scratch
2) copy someone else’s code
3) skip the math and use pure lookup tables.
1 was a bit out-of-scope based on my initial goals, so I decided on a blend of 2 and 3. My implementation uses lookup tables for S-boxes and MixColumns. There are some reference/example implementations out there that use no lookup tables, and some other people doing exactly what I’m doing using the same approach, but as I mentioned it looks like most production implementations use hardcoded full lookup tables – the round operations of SubBytes -> MixColumns -> ShiftRows -> AddRoundKey are reduced to LookupTable -> AddRoundKey. For example, the builtin Golang implementation of AES uses full lookup tables. This leaves a smaller surface area for bugs, but mostly it’s just way faster than calling multiple-instruction functions for Galois multiplication on every single round. This is assuming the CPU running these instructions has at least 24kB of data cache, which is a safe assumption for any modern x86 CPUs.
After I finished the project, I had the mental energy and motivation to actually sit down and get comfortable with Galois fields. I did this using this lecture and this Wikipedia article. I’m struck by the blatant overlap between multiplication in extension fields and bitwise operations (specifically XOR) – weird stuff.
The rest of the implementation was mostly straightforward – lots of test cases and higher-order functions. I did run into a brutal snag at the end, though: once I had successfully implemented the entire algorithm (key expansion, SubBytes/ShiftRows/MixColumns/AddRoundKey, and encryption/decryption) and verified that it was reversible (dec(enc(plaintext)) == plaintext), I compared the output of my function to the NIST test vectors. My code was doing something wrong – even though I had compared each complex function (key expansion, SubBytes, MixColumns)’s output to test vectors successfully, the assembled block cipher wasn’t behaving as expected. I pored over the code and the Wikipedia articles on AES for a while with no luck, then decided to do some in-depth print debugging.
This was a bit tricky though, because (as I mentioned) most implementations of AES just use large lookup tables instead of separate functions. I eventually found a solid Python3 implementation, and adapted it to do very thorough print-debugging, round-by-round:
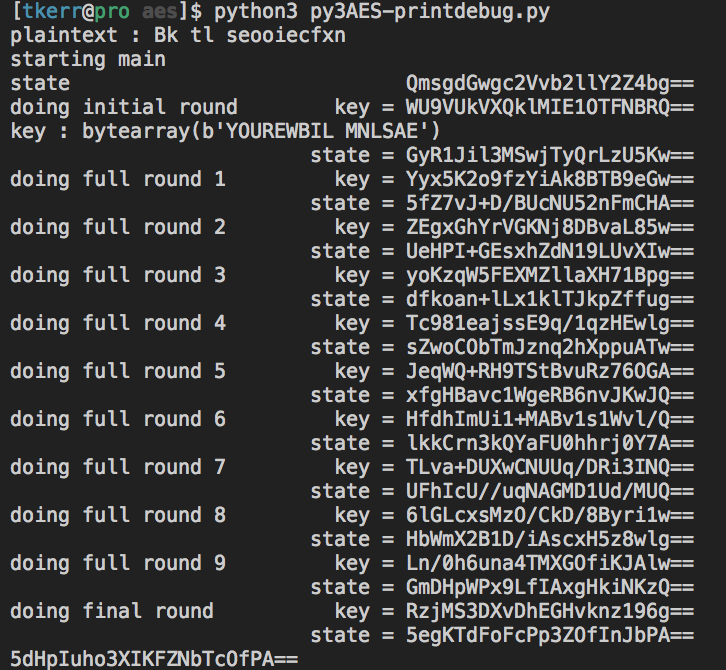
After getting that set up, the issue was immediately apparent: I had skipped Wikipedia’s introductory paragraphs of the cipher description, which includes this very important item:
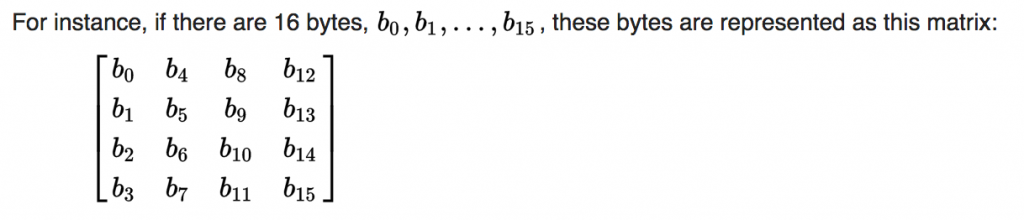
I wasn’t ‘rotating’ the state and roundkeys from the (normal) row-major order into column-major order. Performing this ‘rotation’ on each round key and the input/output resolved the issue and resulted in code that does the exact same thing as every other properly working implementation of low-level AES.
All in all an extremely satisfying endeavor. I ended up reading along the way that more modern ciphers (e.g. ChaCha20) are vastly simpler than AES/Rijndael, so I may attempt one of those in the near future.